
Following our introduction to hash keys, in this second article we provide detailed examples of how they work and the advantages they offer over sequence-generated surrogate keys.
Maintaining key relationships through migration
In our previous piece, we shared an example of sequence numbers. Now, continuing with that example, if we needed to rebuild the data model in a new environment, it’s possible that the sequence values would be calculated differently per business key (Customer Number). If we rebuilt the table, the combination of surrogate key to business key could be reordered and be entirely different after processing if we’re using a sequence. Even if we ordered the data first, new records coming in could change the sequence if we rebuild a table in full. Not so with hash keys, where a specific business key will always resolve to the same hash value. This is true regardless of technology, as a single hashing algorithm will give the same result in different supported technologies – here’s the same example using the “Hello World” input strings but in SQL Server instead of Oracle:
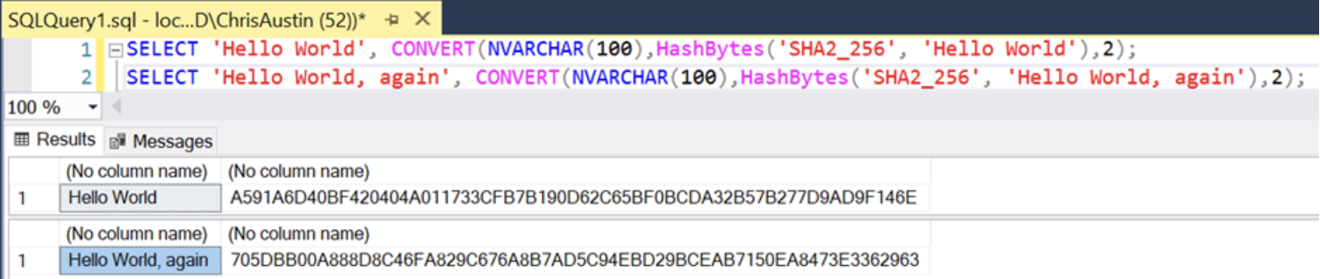
Note the different syntax for SQL Server to call the SHA-256 algorithm, but the same result.
One major advantage here is that our surrogate key to business key relationship could be maintained even if we migrated our system from Oracle to SQL Server, or vice versa. If we needed to achieve the same using sequences, we’d have to factor the migration & maintenance of these sequences into our plan.
Time and efficiency savings
Within the data warehousing scenario, during data processing it’s usually a requirement to build/calculate dimension tables first and then fact tables second. This is because we need the dimensions to have been processed before we can query them to pick up the dimension tables’ primary keys which are populated into fact tables as foreign keys.
Consider the following example of a customer dimension and sales fact table.
Customer Dimension
|
Surrogate Key |
Customer Number |
Customer Name |
|
1 |
12345ABC |
Jane Smith |
|
2 |
23456DEF |
John Jones |
|
n |
… |
… |
Sales Fact
|
Order Quantity |
Unit Price |
Customer Key |
Other foreign keys… |
|
2 |
5.99 |
1 |
… |
|
1 |
9.99 |
2 |
… |
Before we can build our fact table, we need to know which surrogate key value is assigned to which customer number in order to join to the correct customer record based on the surrogate key values. This means the customer dimension has to be built before we can confidently process our fact table.
But what if we used hash keys as our primary, surrogate keys? We could build the dimensions and facts in parallel, since the customer number will result in the same surrogate key value each time.
Customer Dimension
|
Surrogate Key |
Customer Number |
Customer Name |
|
6446D58D6D… |
12345ABC |
Jane Smith |
|
705DBB00A8… |
23456DEF |
John Jones |
|
n |
… |
… |
Sales Fact
When processing the fact, we can simply apply the hashing algorithm to the customer number to acquire the foreign key rather than having to join to the Customer Dimension table.
|
Order Quantity |
Unit Price |
Customer Key |
Other foreign keys… |
|
2 |
5.99 |
6446D58D6D… |
… |
|
1 |
9.99 |
705DBB00A8… |
… |
This could save us a lot of time spent processing the join between facts and dimensions, and allow us to load our facts & dimensions in parallel rather than sequentially.
It’s important to note that this advantage doesn’t apply where we are using effective dates to make joins in our data. For example, if the event of the sale in the fact table above needed to join to a customer dimension record at the point of time of the sale, our join would need to be more complex. Here we might need to match on the Customer Number and the date of sale being BETWEEN the effective dates of a specific customer record.
For example:
Customer Dimension
|
Surrogate Key |
Customer Number |
Customer Name |
Effective From |
Effective To |
|
1 |
12345ABC |
Jane Smith |
01/01/2022 |
31/12/2022 |
|
2 |
12345ABC |
Jane Jones |
01/01/2023 |
31/12/9999 |
|
n |
… |
… |
|
|
Sales Fact
|
Order Quantity |
Unit Price |
Sale Date |
Customer Key |
Other foreign keys… |
|
2 |
5.99 |
01/06/2022 |
1 |
… |
|
1 |
9.99 |
01/07/2023 |
2 |
… |
In this example, the join would need to be on Customer Number and date is BETWEEN the Effective From and Effective To dates in the dimension. Both records in the fact relate to the same customer, but at different points in time. Hence, the sales records need to join to different rows in the Customer table. This is not something that we can calculate using hash keys independently within the fact and dimension processing using a hash of just the Customer Number.
Better performance and outcomes
Back to the advantages, we can also use hash keys to improve the performance of our update logic using a field known as a hash diff.
Imagine we have a table with several fields we’re interested in from a source system in a type 2 slowly changing dimension (SCD).
Note: for a type 2 SCD, we’d want to create a new record with effective dates every time a value changes in the fields we’re tracking, and ‘end date’ the previous record. It’s worth a quick google on how SCDs work if you’re not familiar.
Every time we process our data, we need to validate that per ID, all of the fields below are the same between source and target to validate whether we need to perform an insert/update.
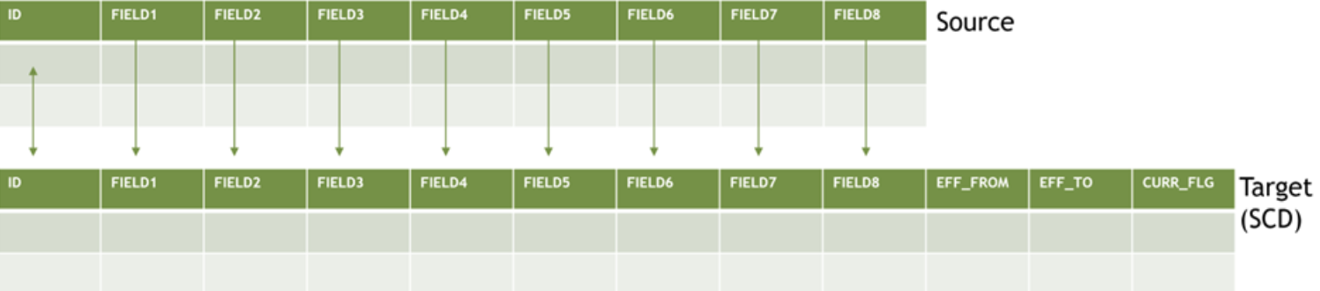
<p dir=" alt="">If any of the values in fields one through eight have changed, we need to insert a new row and update the effective date of the previous row per ID.
Depending on the number of fields, this could be a costly operation – we could have many dozens of fields we need to compare between source and target.
If we used a hash key, we could define a hash value that is a concatenation of all of the fields we’re interested in tracking, and just limit our lookup to this single hash diff field:
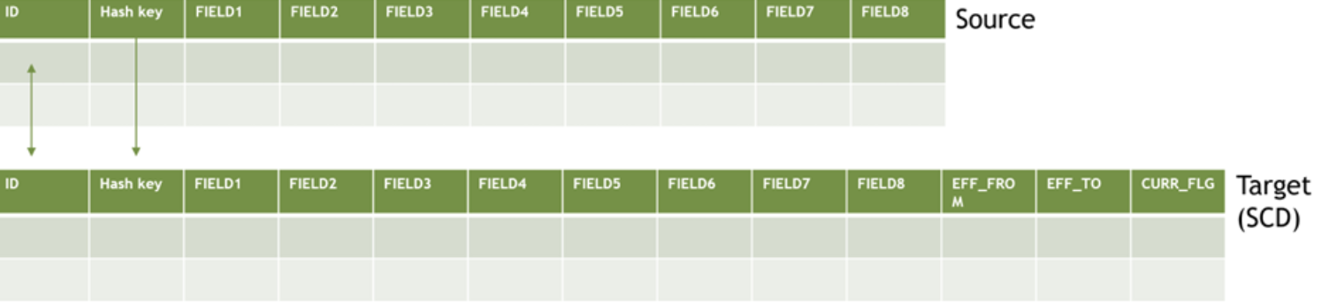
Here the hash key field would be the function of a concatenation of fields 1 through 8. Then, if any of the fields are different between source and target, we know we need to update the row or add a new row, having only had to compare a single field.
Finally, we can use hash keys to shorten what could be long ID fields. In some situations, a unique identifier for a row needs to be a concatenation of multiple different fields. If we’re having to concatenate dozens of fields of varying lengths, we could end up with a massive string which threatens to break the 4,000 byte limit of a standard VARCHAR2 data type in an Oracle database, for example. Instead, we could concatenate the field and pass the result into a hashing algorithm and produce a unique ID that’s limited to e.g. a 64 character string using SHA-256.
Queries and collisions: The challenges of hash keys
Hopefully you’ll agree that hash keys have some great benefits, but as with everything, there are some downsides.
We’ve covered that hash keys don’t offer advantages for processing when we need to join using effective dates. We’ve also mentioned that performing joins on integer values is generally more performant than on string values. If we use hash keys for our primary/foreign keys in a data warehouse, we will be sacrificing some performance in analytic queries trying to join facts and dimensions together. It’s always worth testing performance of queries & reports before committing to this approach. Within the community of hash key practitioners, the benefits listed above RE data load performance are generally considered worth the trade off for query performance.
There is also a chance of what’s known as a ‘collision’ when using hash keys – i.e. multiple input strings resulting in the same hash value. This could be a problem as it could cause a primary key violation within the database. Depending on the hashing algorithm used, this chance is almost infinitely small. It’s estimated that for the SHA-256 algorithm used above, all of the hard disks ever produced on Earth wouldn’t be able to hold enough 1MB files to generate even a 0.01% chance of a collision, so practitioners of the hash key approach generally consider it a risk worth taking. Depending on the algorithm being used, you’re statistically more likely to have a meteor hit your data centre than suffer a hash key collision.
Used sensibly, hash keys can offer some handy performance improvements for data warehousing solutions. It’s always best to test how various hashing algorithms are supported on the technologies in scope for your project before using them in anger. It’s also sensible to test the performance impact for analytic queries using expected production data volumes before committing to them as an approach for surrogate keys. But even without full implementation, techniques such as hash diff can be really useful when optimising code, benefitting companies and data warehouses everywhere.

Hash keys, the unsung hero of data warehousing - Part 1
In our first piece on the subject, we examine what hash keys are and how they can have an impact on your data warehouse solutions.
Read more
Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-
-

Reimagining case management across secure government
Read blog post -
