
Hash keys are a relatively unknown and unused entity when it comes to data storage and management (AKA data warehousing), but their potential benefits should not be ignored. They can be used to offer significant performance improvements within data warehousing scenarios, while also offer robust repeatability and consistency in outputs of surrogate key generation, simplifying data migrations and data processing workloads.
In this article series, we will share how hash keys can have an impact on your data solutions. In our first piece, let’s set the scene…
Data warehousing and surrogate keys
Within data warehousing, it’s common practice to create surrogate keys within the data model for each natural key (AKA business key) value coming from the source data.
For example, a customer might have the customer number 12345ABC. This value may be the natural primary key of the data in the source system, but it’s generally best practice to create a surrogate key which uniquely identifies the record within the warehouse and has no dependency on the business value.
Customer 12345ABC might have a surrogate key value of one. The next customer, whatever their customer number (let’s say 23456DEF), would be assigned the surrogate key value of two in a sequence, and so on.
|
Surrogate Key |
Customer Number |
Customer Name |
|
1 |
12345ABC |
Jane Smith |
|
2 |
23456DEF |
John Jones |
|
n |
… |
… |
There are several reasons we use surrogate keys within data warehousing:
-
They are independent of the source data, so we don’t have to worry about changes to the source system impacting our primary keys
-
Surrogate keys allow us to preserve the history of changes in the source system by creating a new row with a new key each time a record is updated in source (where the business key would not change)
-
As integer values, surrogate keys provide a faster join between tables than what could be a long alpha-numeric value in the form of a business / natural key (i.e. it’s quicker to join values like 1 to 1 than 12345ABC to 12345ABC)
Surrogate keys are often assigned via sequence values, which can be manually defined within the database and referenced by data processing code or created in situ within table objects via identity columns.
The (hash) keys to the future
But recently, the standard practice is beginning to shift towards using hash keys instead of sequence values to assign surrogate keys, particularly within the data vault 2.0 approach to data warehousing.
A hash key is the output from a hashing algorithm, where a specific input value is transformed into a distinct, unique string per input value.
The purpose of hash keys in this context is to provide a surrogate key for business keys, composite business keys and business key combinations. This is done using a hashing algorithm instead of via a sequence.
Below is an example of passing in a couple of strings into the SHA-256 hashing algorithm within an Oracle database:
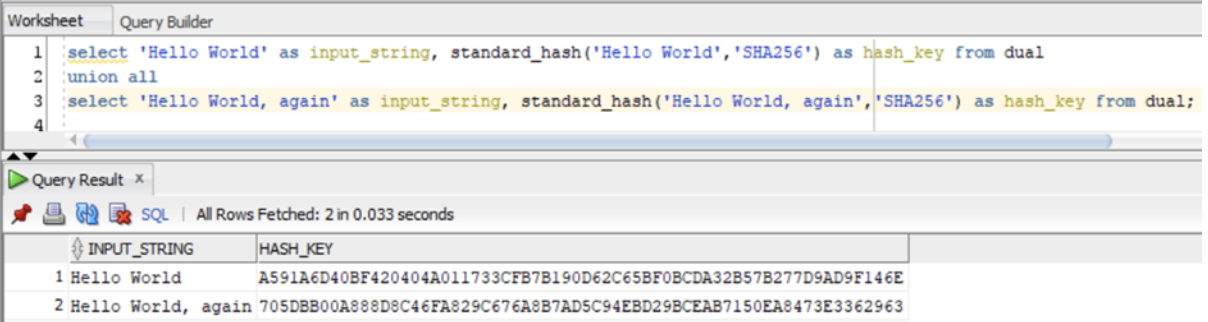
As we can see, the two different input strings each produce their own bespoke hash key.
The algorithm to produce the hash value is case sensitive, so any change to the input string will result in a unique, distinct output value. The same goes for things like trailing spaces, null values etc.
Within the context of data warehousing, the purpose of the hash key is to replace the sequence-derived surrogate key.
So, why would we do this? The use of hash keys follows the principle of idempotence – i.e. the property of certain operations in mathematics & computer science producing the same result regardless of the number of applications.
Now that we’ve set out what surrogate keys and hash keys are, in our next piece we’ll delve into examples of how hash keys work and will benefit your data warehouse and processes.

Moving data from legacy systems into Azure SQL
In this blog post, Head of Technology Mark Carton, delves into two Microsoft tools used to move data from legacy systems to Azure SQL.
Read more
Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-
-

Reimagining case management across secure government
Read blog post -
