The rapid development of technology like Cloud, IoT and AI, along with its subsequent democratisation, is putting powerful tools in reach of organisations of all sizes. In this post I explain how TPXimpact’s Data & AI team worked with Durham County Council to ingest, enrich and index heritage content from across organisations into a single point of search.
Background to the technical challenge
Durham County Council asked us to bring together content from multiple heritage collections into a unified, enriched and searchable index. There were two reasons for this:
- Creating a search index, rather than building out applications and user interfaces, would allow Durham CC to have the infrastructure and knowledge needed for any future innovations.
- Enabling a google-style search on materials, means content would be easier to find. Previously, users had to search across different websites for a variety of content; ranging from images, oral histories, recordings and newspapers, to historic catalogues, indexes and records. This presented a separate challenge since collections were catalogued, classified and managed differently depending on where they were held.
Collaborating with staff at Durham County Council, as well as providing education, training and guidance for managing and enhancing the project and future cloud provision were all important in how we approached the project. In terms of technology, we considered the mechanisms needed to import data into a cloud environment; how to apply technologies (such as AI) to help identify duplicates and enrich the content metadata, and we also needed to create suitable endpoints for accessing the search index.
Technical approach
The basic stages of the project were as follows:
- Requirements: To fully understand the problem and domain in which the solution was being deployed, we talked to staff outside the immediate project team and created a set of clear (and prioritised) requirements.
- Data acquisition and pre-processing: we collected examples of data to be indexed, talked to staff to better understand it and where it needed cleaning. Later on in the project we created pipelines to access the source data to enable updates.
- Architecture and design: this involved designing the metadata schema needed to integrate collections, develop the search index and build out the cloud infrastructure needed to support the search service.
- Development: We built data pipelines and implemented code within our cloud-based platform of choice for this project, which wasMicrosoft Azure.
- Test and feedback: regular evaluation of the ingestion, enrichment, indexing processes were carried out together with sharing updated versions of the search index amongst the project team for review.
These stages were conducted iteratively over four phases which included:
- initial Azure setup, review of data sources and requirements specification
- initial architecture and technical development, indexing pipelines on selected collection
- further development and integration, indexing further collections
- test and refine an end-to-end solution.
Technical workflow overview
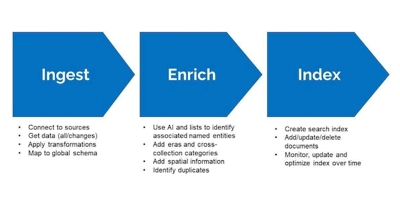
The three parts to the workflow were ingest, enrich and index (as shown below):
Ingest
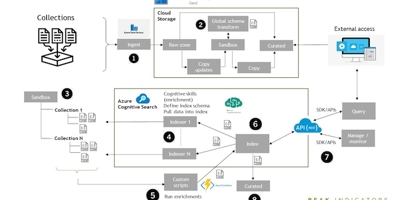
In this initial stage, data from source systems is ingested into cloud-based storage in the form of a data lake. This creates separation between the source systems and the content used for the search index. Within the cloud store, the data is moved between containers to enable easier management. Initially, all data from the source systems is loaded and processed. After that point, any updates are identified and transferred to a ‘sandbox’ area for processing (index).
The approach we used to integrate the different collections is based on mapping fields from metadata in the source collections to a common data model called Dublin Core. This provides a common set of metadata fields (title, description, created date) for further indexing. We based the global schema on Dublin Core; a standard for representing digital resources which is widely used across sectors. At this stage we also carried out initial data transformation and clean-up, including converting dates into a common format. Diagram of the project below:
Enrich
All data and updates from the collections are enriched and indexed through an ‘indexer’ within Azure Cognitive Search (shown in point 4). After this enrichment and further transformation, it passes into the indexing process (6). We created a separate indexer for each collection, or similar source data, where collection-specific processes can be applied. The indexer can also be scheduled to run at set intervals or when changes are detected to update the index. We built custom scripts (5) outside of the indexer pipelines that can add custom enrichments and push data into the index (instead of pulling data, which is what the indexer does).
The main general enrichments we applied were: identifying keywords and named entities from unstructured text; mapping dates to a predefined list of eras and mapping subject-specific categories to a predefined list of cross-collection themes or topics.
Index
The index structure must be defined in advance where the index fields and their attributes are defined. Examples of this is whether a field is sortable, filterable or searchable. The enriched data in JSON form, matched to the global schema, is mapped onto fields in the index.
The index itself is built and made available through REST APIs (7) which can be used to query the index or manage/monitor it. The index can also be exported and stored on the cloud storage in a curated area (8). This enables further access to the enriched datasets, for people who want to use it for analysis. The overarching data ingestion and management pipelines keep the index fed with updates or new content detected in the source collections.
Technologies used
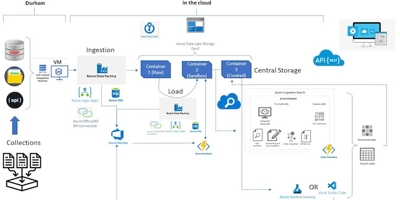
The solution was developed and deployed using Microsoft Azure. The main resources were: Gen2 Data Lake Storage (ADLS), Azure Data Factory (ADF), Azure Functions, Azure SQL Server, Cognitive Search and Cognitive Services. More detail of this is in the table below. Further resources included the standard networking, Azure Logic Apps and key vaults. For connecting the cloud-based ADF pipelines to the on-premise data stores we made use of a self-integration runtime Virtual Machine (VM) solution to provide the required levels of security.
Azure gave us the flexibility and scalability needed to create and deploy the solution for this project. Development work was undertaken on a local Azure tenancy for the TPXimpact Data team, and then deployed into the Durham tenancy when the solution reached an acceptable level of performance.
One of the key resources used in this project was Cognitive Search, which is a standard Azure resource . This is a fully managed Platform as a Service resource available within Azure and based on the Lucene open source search engine from Apache. Not only does this enable full text search capabilities, including indexing, query matching and ranking, but also takes advantage of Cognitive Services to allow various forms of document enrichment. The table below summarises some of the key features of Cognitive Search and how we used them within the Durham project.
Key features of cognitive search
| Cognitive search feature | Description | How we used the feature |
| Indexers | Indexers automate data import and control document enrichments | We created indexers for major collection types where indexing attributes (e.g., refresh time, enrichment pipelines) could be configured |
| Indexing | Indexing pipelines accept JSON input and can handle hierarchical and nested data structures | We integrated datasets into a global schema represented in JSON. This was fed into indexing pipelines |
| AI enrichment | AI processing during indexing using in-built and custom skillsets | We used a combination of AI and post-filtering with controlled vocabularies to identify keywords and named entities |
| Free-form text search | Full text search using simple or full Lucene query sentence | The rich query syntax allows for querying the index using fuzzy and proximity matching, term boosting etc |
| Relevance ranking and scoring | Ranking based on traditional term weighting and scoring profiles | We used out-of-the-box relevance ranking to order search results |
| Document sorting | Index fields can be made sortable to complement relevance ranking | Fields in the global schema such as date were enabled for sorting to better service certain queries |
| Geospatial search | Native in-built support is provided for basic spatial search capability | Spatial coordinates in the metadata were added to collection records where possible to enable retrieval based on distance from point and within polygon |
| Facets and filters | Facet and filter queries enable support for user navigation beyond querying | Faceting and filtering was enabled on metadata fields to support filtering and cross-collection navigation |
| Autocomplete | enables type-ahead queries in a search bar | Supports the users search experience within a UI |
| Hit highlighting | Applies text formatting to a matching keyword in the search results | Supports the users search experience within a UI |
| Synonyms | Can add alternatives for query terms to improve query matching | Synonyms were used to allow matching alternates, such as abbreviations |
| Search suggestions | Provides suggested document matches as users input queries | Supports the users search experience within a UI |
| Tools for prototyping and inspection | Import data wizard, search explorer and create demo app | These tools were used to evaluate and demonstrate these tools to shareholders at Durham County Council |
Key Learnings
Some key technical takeaways from this project were:
-
Know your data and domain: the project was rooted in cultural heritage and information science, as well as being technical. We spent time getting to understand the domain in addition to the various rounds of data probing and analysis we did to understand the data.
-
Keep it simple, stupid (KISS): we applied the KISS principle to create a fully deployed working solution rather than something more complex involving sophisticated functionality. For example, in some cases this involved utilising simpler rule-based methods than more complex AI.
-
Start small and build up: we started by indexing one of the simpler collections to begin with to get some of the infrastructure in place and added more content after that. We had a broad understanding of the indexing requirements of all collections from the outset. We needed that to ensure areas, such as our global schema, would be suitable as the work progressed.
-
Having the end goal in mind: For the technical work in this project the end goal was case building an automated end-to-end solution and managed search service accessible via a REST API. A useful feature of Azure Cognitive Search was being able to generate a demo HTML web application for an index. This provided a tangible output that we shared with the project team and helped to visualise how the index might be used by a web application and the implications of decisions made during enrichment and indexing.
-
Managing costs: the advantage of cloud-based solutions is the flexibility and scalability you get through consumption-based pricing, but the financial cost must be managed carefully over time. One approach is to start with free pricing tiers to experiment and develop and then move up tiers when ingesting more content and deploying the solution.
-
Involving multiple stakeholders: Last, but not least, was the collaboration with developers from IT and collection owners/managers at DCC. Getting people involved helped to bring different perspectives on the work; keep them in the loop and create a sense of ownership.

Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-
-

Reimagining case management across secure government
Read blog post -
