The CSV format has proven enormously popular in the open data world. Historically, faced by so much data being published in PDFs, the CSV format was a byword for machine-readability.
Its enduring popularity is no doubt helped by the fact that CSV files are near universally accessible. Practically everyone has access to a spreadsheet program — like Microsoft Excel — to read and write CSV files. Unlike Excel’s proprietary XLS format, the humble CSV is also easy to use programmatically; you don’t even really need to use a library.
CSV does have some problems, however.
Although the IETF published a standard — RFC4180 — for CSV in 2005, there are still a wide range of interpretations to be found in the wild. These different dialects of CSV take different approaches to quoting fields and escaping special characters. That’s not to mention differences in encoding that plague any text format.
It’s also not possible to say in advance how the fields in CSV file ought to be interpreted — i.e. their data type. You have to read a few lines of a file and take a guess from these initial rows — i.e. “I’ve not seen any letters in this column, only numbers, and no decimal points so it’s probably an integer variable”. There are clever tools for doing this guesswork for you, but the majority of programs that read in CSV files need to devote a few lines to interpreting the data. Typically this will be to parse dates or give the columns syntactically-valid variable names.
Despite these problems, CSV has become the lingua franca of open data, and not without good reason. It’s an incredibly simple way to reach the third star of the 5 star deployment scheme for open data:
- ★ you can publish CSV on the web (with an open license)
- ★★ CSV is a machine-readable table
- ★★★ CSV is non-proprietary
But what about the final 2 stars? On it’s own, CSV doesn’t really help you to achieve those:
- ★★★★ using identifiers to denote things, so that people can talk about your resources unambiguously
- ★★★★★ linking your data to other data to provide context
These are the distinguishing characteristics of linked-open-data. These features enable data from different sources to be connected and queried, forming a web of data. This network is most strikingly depicted in the linked-open-data cloud.
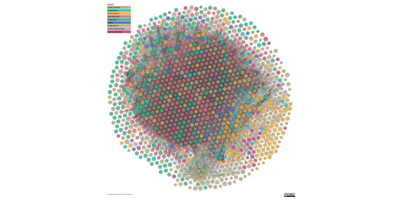
Publishers wishing to contribute to this cloud, or leverage the informative context it can provide for their own data, have to shift their perspective from a tabular view of the world with its rows, columns and cells to one of graphs, nodes and edges.
They have also had to abandon CSV along the way and instead learn a new set of technologies like RDF ontologies and SPARQL queries.
It’s against this backdrop that a W3C working group set out to provide recommendations for working with CSV on the Web. This “CSVW” standard provides a way to resolve the problems with CSV (standardising dialects and expressing types) and to extend it with identifiers to make 5 star linked-data in CSV format. In practical terms, this means associating your CSV file with a JSON document that provides some addition metadata to describe and clarify the content of the CSV table.
The UK Government has recently adopted the CSVW standard and recommend that government organisations:
"use the CSV on the Web (CSVW) standard to add metadata to describe the contents and structure of comma-separated values (CSV) data files."Central Digital and Data Office
Using metadata to describe CSV data
We’re delighted to see the power of linked-data being brought to the venerable CSV format and hope that this will ensure its continued popularity for many years to come.
If this has whet your appetite, the next tutorial in this series on how to create your own CSVW is coming soon.

Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-
-

Reimagining case management across secure government
Read blog post -
