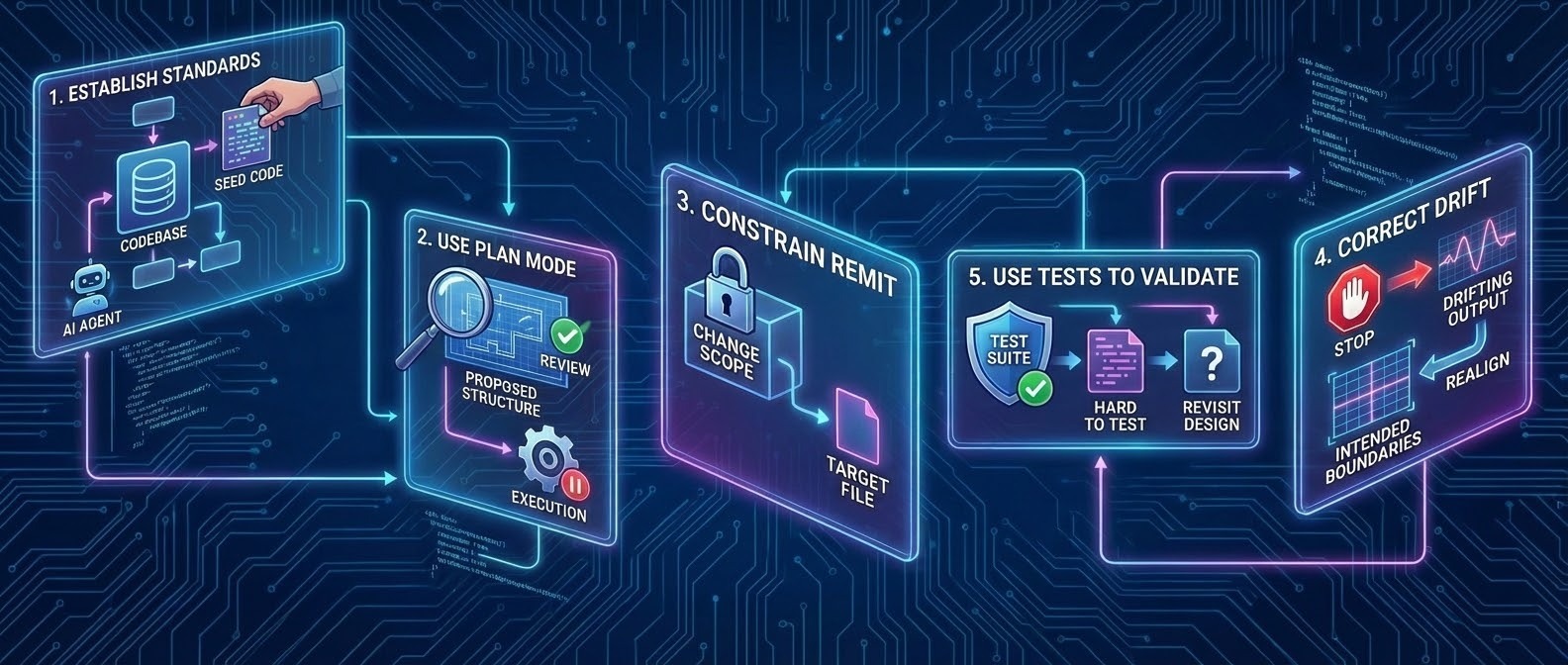
Practical takeaways
-
Establish standards before generating features:
Seed the *codebase with clear examples of structure and patterns so the agent has concrete logic to follow. -
Use plan mode before letting the agent write code:
Review the proposed structure, dependencies, and boundaries first. Treat execution as a second step, not the default. -
Constrain the agent’s remit:
Be explicit about what the change is allowed to touch;keep the scope narrow, so it’s easy to review -
Correct structural drift explicitly:
If the output doesn’t match your intended boundaries, stop and realign rather than fixing around it. -
Use tests to validate structure:
If a change is hard to test, treat that as a signal that the design needs revisiting.
I’ve been building software professionally for a long time. I’ve shipped large systems and have reviewed more PRs than I can count. Because of this, I am deeply sceptical of the *vibe coding trend. You cannot simply prompt an AI and expect a production-ready system to appear
But I am interested in how new AI coding techniques keep engineers in control.
I set out to build an application using a strict *spec-driven development workflow: To do so, I used an AGENTS.md file as a contract, wrote a Markdown spec, and let an AI agent generate the code.
There was no back-and-forth prompting and no manual patching. My goal was to understand which engineering disciplines still matter when implementation becomes cheap.
And the experiment worked. I built a functional, complex system much faster than I could have produced alone, but the most important lesson wasn’t about speed.
It was this: AI follows both intent and precedent.
Unless you deliberately set a clear precedent, AI-assisted development tends to accelerate whatever structural confusion already exists.
What I’d front-load next time
If I were starting again, I wouldn’t repeat the journey exactly. I would front-load far more constraints from day one:
- A fixed project structure, with clear boundaries between layers
- Specs that prevent wandering rather than merely describe intent
- A stronger “constitution” that defines what the system is not allowed to do
The experiment worked only because these constraints eventually existed. In hindsight, I should have pushed the agent into a planning phase earlier. The issue was not automation itself, but rather, when I chose to let it run rather than stop and evaluate.
Early decisions and structural drift
Early on, I allowed the agent to bootstrap the project from a high-level spec. Nothing was technically broken, but the result felt wrong: mismatched conventions, out-of-date package versions, and an awkward structure.
That was the first sign.
Starting a project is a high-risk phase for automation; this is where defaults leak in, and uncertainty gets locked into the design. If you do not establish a clear precedent here, you will create future friction. I reset, manually established the structure (yes, I had to step in), and continued. Even then, structural drift crept back in.
When documentation is not enough
The first real feature worked, but structurally, it mixed responsibilities that should have been separate. I did not like it, but I accepted it, assuming documentation would be enough to steer future changes.
It was not.
I clarified the rules in writing and asked the agent to add the next feature. The resulting structure repeated the earlier pattern. In practice, when written guidance and existing code disagreed, the existing code seemed to carry more weight. Concrete examples tend to outweigh abstract instructions in automated systems.
The early precedent was structural: too much responsibility collapsed into the route layer. Validation, data access, orchestration, and response shaping all lived together. While nothing was broken, the separation of concerns was compromised. That structure made tests harder to write and made change riskier. Crucially, it became the pattern for future changes.
Technical debt becomes an instruction
This reframes how I think about technical debt in agile delivery. Traditionally, debt is a future maintenance problem. In AI-assisted workflows, it is immediate: it shapes what the AI produces next.
By accepting a “good enough” structure early on, I was not merely delaying cleanup. I was normalising that structure as acceptable and telling the AI to copy it.
Tests reveal structural issues
The real breaking point was testability. Once responsibilities were tangled, even simple tests needed excessive setup and mocking. The tests were simply compensating for poor structure.
That was the signal. If code is hard to test, that’s rarely a tooling problem. It’s usually a boundary problem. Tests became my fastest feedback loop for detecting architectural drift.
From negotiation to control
At that point, I stopped trying to “ask” the agent for better outcomes; the system was behaving consistently, just not how I expected.
Documentation helped, but code was still the real authority. I wrote a refactor spec to realign the codebase with the rules it claimed to follow (and to align with changes in my AGENTS.md file.) With better judgment earlier, I likely would not have needed a refactor at that scale. Stronger boundaries would have limited the drift before it built up.
However, the refactor still worked. It corrected the precedent, aligned the structure with the intended boundaries and allowed progress to continue safely.
Once the structure matched the rules, the AI’s behaviour changed with it.
Why constraints beat guidelines
Automation does not invent standards; it copies them. If validation, error handling, or layout discipline aren't present early on as concrete, copyable examples, they don’t reliably appear later, no matter how clearly they’re described.
Seeding a small number of canonical patterns that the system could assemble from seems to have a profound effect on the output.

The universal failure mode
This pattern isn’t unique to application code.
Vague UI ownership leads to visual drift.
Unclear service boundaries lead to untestable systems.
Weak data contracts lead to unreliable outputs.
At an organisational level, fuzzy foundations lead to AI pilots that never survive production. The failure mode is consistent: when foundations are vague, automation does not help; it accelerates entropy. This is not a claim about how AI works internally; it is an observation about what happens when automation meets underspecified systems.
A note on legacy codebases
In long-lived codebases, this dynamic is even more important.
Precedent already exists, and it’s rarely consistent. Styles, patterns and assumptions build up as teams change over time. In that environment, spec-driven development only works if change is deliberately isolated.
You don’t ask an agent to “modernise the system”. You constrain it to thin, controlled slices of change with explicit remit, small diffs and fast review cycles. Otherwise, the AI doesn’t improve the codebase; it reproduces its mixed history at scale.
The payoff: Velocity with control
Once structure, constraints, and examples were aligned, something shifted. I could write a small, focused spec, and the agent would generate changes across multiple layers in one pass while sticking to my seeded standards.
[example purposefully abstracted]
Spec 010 — Add a new entity
Goal
Allow an authenticated user to create a new record through a dedicated page.
Acceptance Criteria
-
-
-
A dedicated "add" page exists at /entities/new and is accessible to authenticated users only
-
The page renders a form containing all required fields
-
Required fields must be completed before submission is allowed
-
Submitting a valid form creates the record and redirects the user to the list page (/entities)
-
If submission fails, the error is displayed inline and the form retains the user's input
-
The page is consistent with the application design system
-
-
(This spec is intentionally simplified for illustration. A production spec would describe: a definition of done, domain validation rules, authorisation constraints, performance budgets, test cases, and data models with schema validation (e.g. Zod enforced through a typed data layer). It would also name specific routes, components, and file paths so that agents have unambiguous targets to work from. It operates alongside an AGENTS.md file which defines how agents interpret and act on specs as a contract.)
Because the high-level engineering decisions were already made, the automation could safely handle the details. Velocity appeared after discipline, not before it.
Emerging techniques
This landscape is shifting quickly. Agent orchestration is an active area of experimentation and the tooling, conventions, and workflows around it are still forming.
One pattern gaining traction is the idea of agents iterating against explicit success criteria across multiple passes, playfully named the “Ralph Wiggum Loop”. Rather than generating code in a single pass and stopping, the agent checks its own output against a defined set of criteria, corrects what fails, and repeats until everything passes. This is a natural extension of the single shot acceptance criteria approach described in this article.
Future agents may become better at untangling large systems, but relying on large-scale repair is still a riskier strategy than maintaining clear boundaries from the start. Changes must remain small, focused, and reviewable by a human. This isn't vibe coding.
From building to orchestration
I wasn’t really “coding” in the traditional sense anymore.
When code generation is easy, the value shifts to knowing what to build, how to structure it and which patterns are appropriate. That is the role shift. AI doesn’t remove the need for engineering judgement.
This approach works only when structure, boundaries, and constraints are in place before the agent starts writing code. It will be interesting to see how the SDLC changes as code generation becomes easier and more of the work moves into design and decision-making.
The engineer as the architect
The experiment confirmed a vital truth for the era of digital transformation: automation does not replace discipline; it increases the demand for it.
When AI executes against well-described decisions rather than substituting for them, we can move faster without losing control. The shift from "building" to "orchestrating" allows us to focus on the high-level decisions that ensure a system is scalable, secure, and effective.
In an agile delivery environment, our role is to set the boundaries and precedents that allow automation to flourish without creating structural drift. As the cost of generating code falls, the value of engineering judgement has never been higher.
Let’s build better, faster
At TPXimpact, we help organisations navigate the complexities of AI integration and modern software engineering. We believe that the best results come from combining innovative tools with proven engineering rigour.
Are you looking to scale your engineering velocity while maintaining high standards?
More from our tech blog
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

Reimagining case management across secure government
Read blog post -

-

-
