Bloomreach is TPXimpact’s Java CMS of choice. The documentation here shows an excellent example of locating all the comments associated with a News article; modelling a classic parent-child relationship.
Sometimes, however, you might want to look at that relationship from the child’s perspective, so in this article we will show how you can use the Query APIs offered by Bloomreach to perform a reverse search on a child-parent relationship.
Relationship status: It’s not complicated
We are going to extend the example to include the names of comment authors:
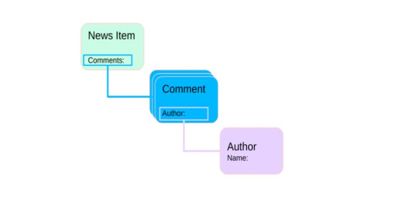
At the moment, it’s easy to find the comments for a news article and it’s easy to find the author for a comment because in both instances, those relationships are established directly in the document type definition. But what if we want to examine an author and see how many comments they have ever made?! We are going to have to reverse the search to find those comment beans.
JCR FTW
One of the reasons we selected Bloomreach was because it has a JCR based repository. The JCR is easily accessible through standard XPath queries, but you can also use the very powerful APIs that Bloomreach have provided to allow programmatic content manipulation, including searching.
Engage!
The search uses an instance of org.hippoecm.hst.content.beans.query.HstQuery . You provide criteria and generate the Query object, execute it and it gives you beans!
So,to create that Query object, supply the following;-
- the actual instance of the Author child bean which must be a org.hippoecm.hst.content.beans.standard.HippoDocumentBean (you will have generated this using the Bean Writer tool in the Bloomreach Essentials tool)
- the document root for your channel
- the attribute name in the parent that holds the child reference (the hippo:docbase reference)
- a bean mapping class of the parent type (Comment) you expect to find (again, that must be an instance of HippoDocumentBean)
- a flag to indicate if subtypes of that parent are also required.
HstQuery query =
ContentBeanUtils.createIncomingBeansQuery(myAuthorInstance,
requestContext.getSiteContentBaseBean(),
"mySite:theAuthorProperty/@hippo:docbase",
CommentDocument.class,
false);
Next, you execute the query to get a result set:
HstQueryResult res = query.execute();
Finally, check the result set to see what you got. The getHippoBeans() method returns an iterator that can be easily inspected.
if (res.getHippoBeans() != null && res.getHippoBeans().hasNext()) {
// do something
(CommentDocument)result.getHippoBeans().nextHippoBean();
}
And really, that is all there is to it. The BloomReach API does all the heavy lifting including additional filtering capabilities as well as options to look deep into the relationships between documents in the system.
All done and dusted
If you’d like to talk a little more about how Bloomreach can be used within your organisation then please do not hesitate to get in contact with us.

Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-
-

Reimagining case management across secure government
Read blog post -
