
It’s not enough to show people the services near them, Google Maps can do that. To make a directory effective, you need to show coverage areas and accessibility information and be sensitive to the problems residents may face.
Following a data standard makes these jobs easier. Once a few directories have a standard in common, it’s easier for others to adopt this information, building on this work to create their own products on top of the existing data infrastructure.
Here’s a look at how we implemented a service directory in a new data standard in Buckinghamshire.
Getting acquainted with the standard
We’re following the OpenReferral UK standard for community services data. It’s new work, so it’s likely that we’ll discover things that can be applied back to future versions of the standard.
The standard breaks data into many tables, so we can represent complicated service offerings. We can represent an organisation that offers lots of services to different groups of people, on different schedules, from different places.
The downside of this complexity is that existing datasets, like the one we’re trying to migrate, are rarely designed with this flexibility in mind. In this case, our starting point was a single spreadsheet with several hundred columns, added at different times by different people. The exact purpose of some lost to history.
Spreading out our data across so many tables also poses a software architecture problem: how do we collect everything the user’s asked for in a reasonable amount of time?
People will be making complicated queries (“show me things in X category, on Y day, near Z location”) and we don’t want to keep them waiting. We need to pay careful attention to database design and caching to prevent queries taking too long.
What we made
From the start, we knew we needed to build a custom front-end for people to explore and browse services, powered by a public, standard-compliant API.
We considered making use of existing open source tools to manage the dataset and publish the API, but were quickly disappointed with the tools on offer, and made a custom rails app instead.
Originally we hoped we could use a basic back-end/front-end split, but the team we were working with were used to surrounding their data with complicated business processes.
We simplified these where we could, but after building several approval and versioning workflows into our app, we realised it was slow and complicated. We were failing at getting all the right data together in a reasonable amount of time.
Introducing MongoDB
Eventually, we decided to add a third component to our architecture, MongoDB, an API service that sits between our back-end and front-end apps. We’ve written about MongoDB before for managing community datasets. The job of the API service is to serve data as fast as possible, without having to go digging through version histories or workflow rules.
You can think of the API service as a “staging area”. It knows that everything in its database is good to share publicly, there’s no need for it to carefully inspect and scrutinize data like our back end app does. That makes it much faster.
Our original choice of database was PostgreSQL. It’s a classic database choice, good for general purpose workloads. No one will raise an eyebrow if you start a new project with PostgreSQL.
For the API service, it turned out MongoDB was a better fit. MongoDB doesn’t have tables, rows and columns like a traditional database. Instead, it stores chunks of JSON data. This is a very close fit to the data we want our API to return, so there’s less overhead when a user requests the data, and we can fulfil the request much faster.
Rather than doing expensive look-ups across several tables, you simply nest all that data inside a single JSON blob, ready to send. MongoDB’s great features for geographic sorting and filtering of results make it a great fit for “I want to see X things near me”.
Augmenting the standard with GeoJSON
Since we started working on this project, a global pandemic has happened. People aren’t leaving their houses as often, and when they use service directories they’re more interested in questions like “who serves my address?” than “where is their office?” So coverage areas seem to be the future, not point locations.
It’s harder to describe an area in data than a point, but MongoDB comes with first-class support for GeoJSON, a toolbox for doing just that.
We can use a familiar syntax to describe polygon areas, filtering and sorting based on whether a user lies inside them. This example describes the area between four points:
{
"type": "Polygon",
"coordinates":[
[[30,10],[40,40],[20,40],[10,20],[30,10]]
]
}
Now, it’s hard enough to geocode a large database of point locations and even harder to reliably define coverage areas, but we want to do the hard work to make things simple.
Taxing taxonomies
We had a similar problem when we came to categorise our dataset according to a standard list. The dataset was already categorised, but there wasn’t much logic or strategy to them, nor much overlap between the lists of recommended standard taxonomies and the ones we had.
Completely replacing the existing categorisation would’ve been a burden on the team we were working with, and there was some evidence that people did understand and find the current list useful.
Instead, we decided to build a flexible taxonomy feature into our app that can handle a gradual migration, rather than a hard switch-over.
What we’d do differently
The value of standards comes from the predictability of interacting with something for the first time: sometimes it’s better not to try than to do a half-finished job.
It’s easy to end up with an app that uncomfortably combines meeting a standard with the unique needs of a particular team. Which should win?
It’s hardest when the standard is new, like this one. Disparities could be clues that the team could be working in a different, better way, or they could be hints that our standard is incomplete and needs to be improved.
When you try to implement standards like this one on your own projects, it’s important to start with a clear idea of which is more important to you; a clear and painless “upgrade path” for your immediate client or the possibilities offered by bulletproof following a standard.

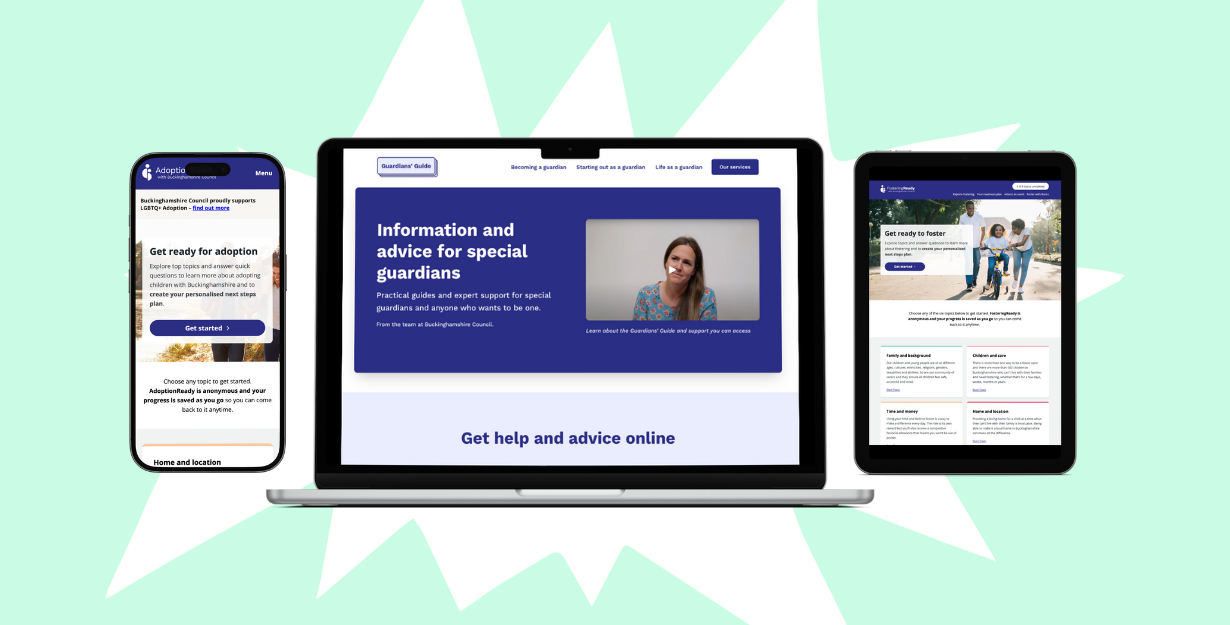
Digital tools empowering residents to care for at-risk children
Creating a groundbreaking suite of new digital tools to support caregivers of at-risk children, provide guidance and drive applications.
Read moreOur recent insights

How local action can transform the UK's path to net zero
Discover the pivotal role of local authorities and communities in the fight against climate change
Read more
Empowering communities: the impact of citizens' assemblies
We spoke to Ellen Jennings, Senior Workstream Coordinator at Barnet Council’s Sustainability Team, about the importance of citizens' assemblies in helping to address the climate emergency.
Read more
Bringing community power to life
Our Community & Political Engagement Director, Claire Hazelgrove, shares her experiences from Stronger Things
Read more